QLoRA Fine-Tuning with EQ-bench 3
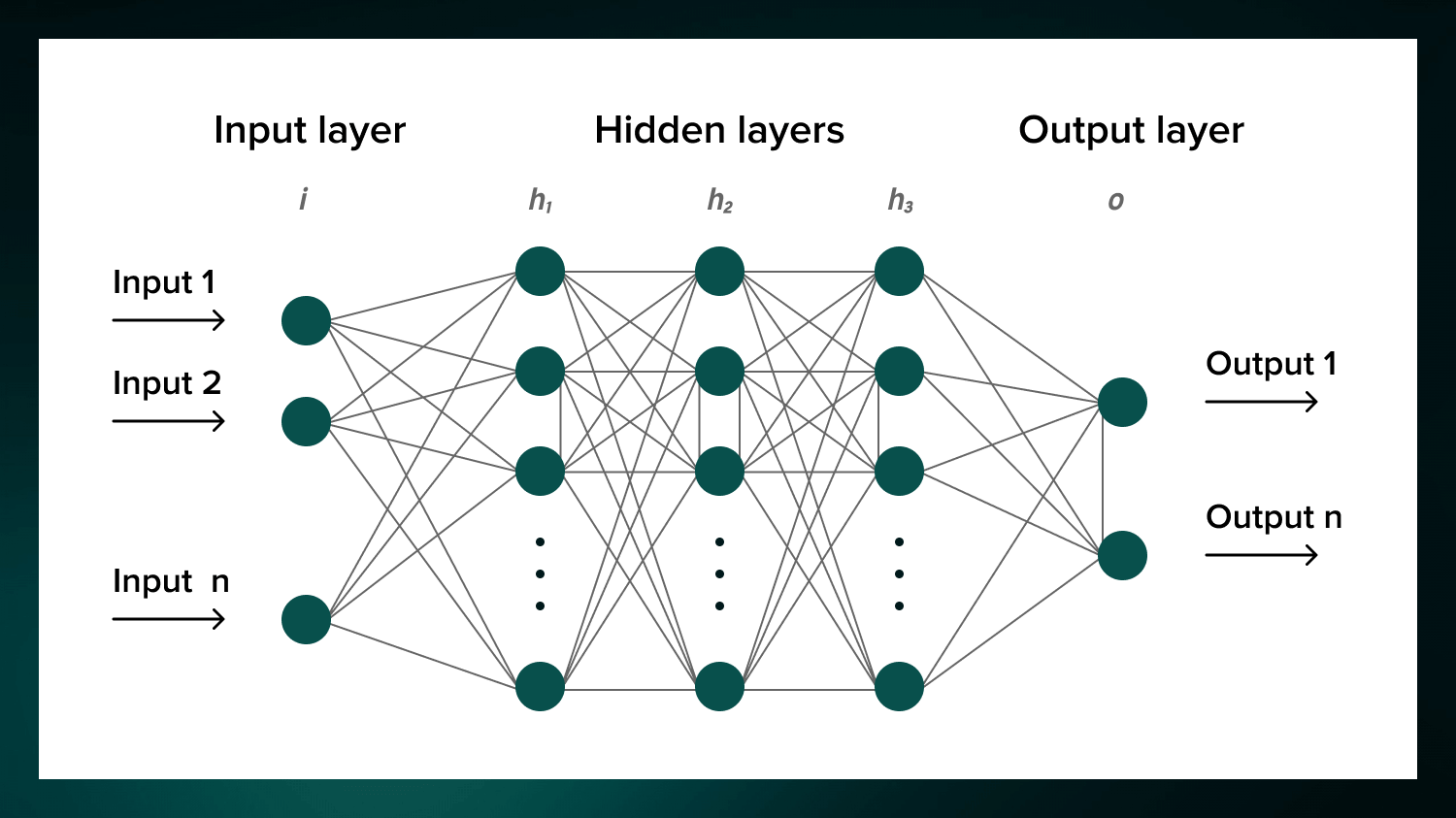
Fine-tune an open-weights LLM into an empathetic best-friend assistant and show measurable gains on EQ-Bench 3. Train with multi-objective SFT using auxiliary emotion and support-strategy heads, then optionally run DPO for alignment. Provide quantitative improvements and brief qualitative insights